2025/01/040件のコメント
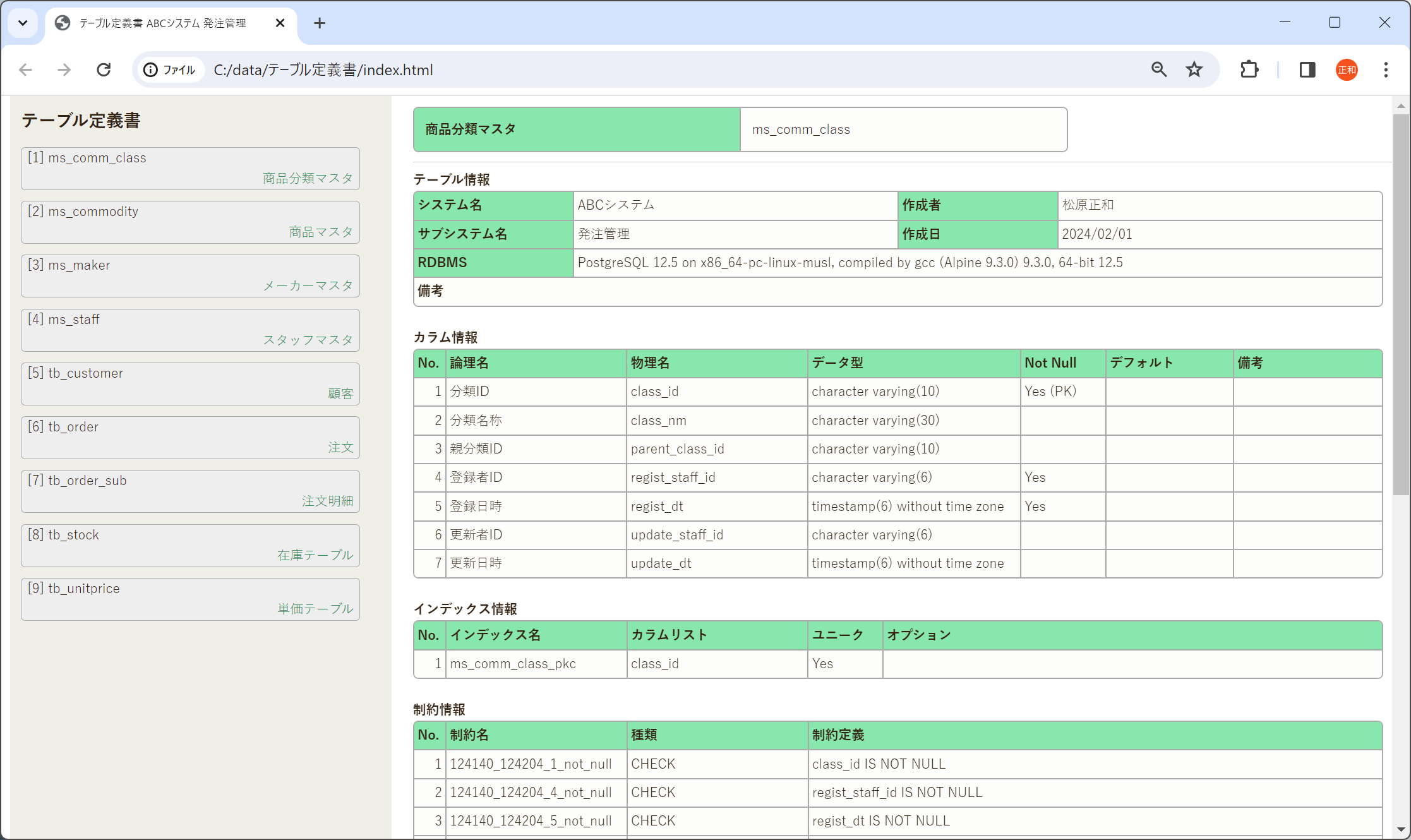
A5:SQL Mk-2 Version 2.20.0 を公開しました。ここではその新機能についてご紹介します。
様々な新機能が追加されましたが、ここでは以下の新機能に絞って説明を行います。
AIアシスタント機能
テキストエディタコンポーネントの置き換え
SSH経由の接続で、Windows OSに付属する ssh.exe を利用できるように変更
1. AIアシスタント機能について
1.1 使う前に
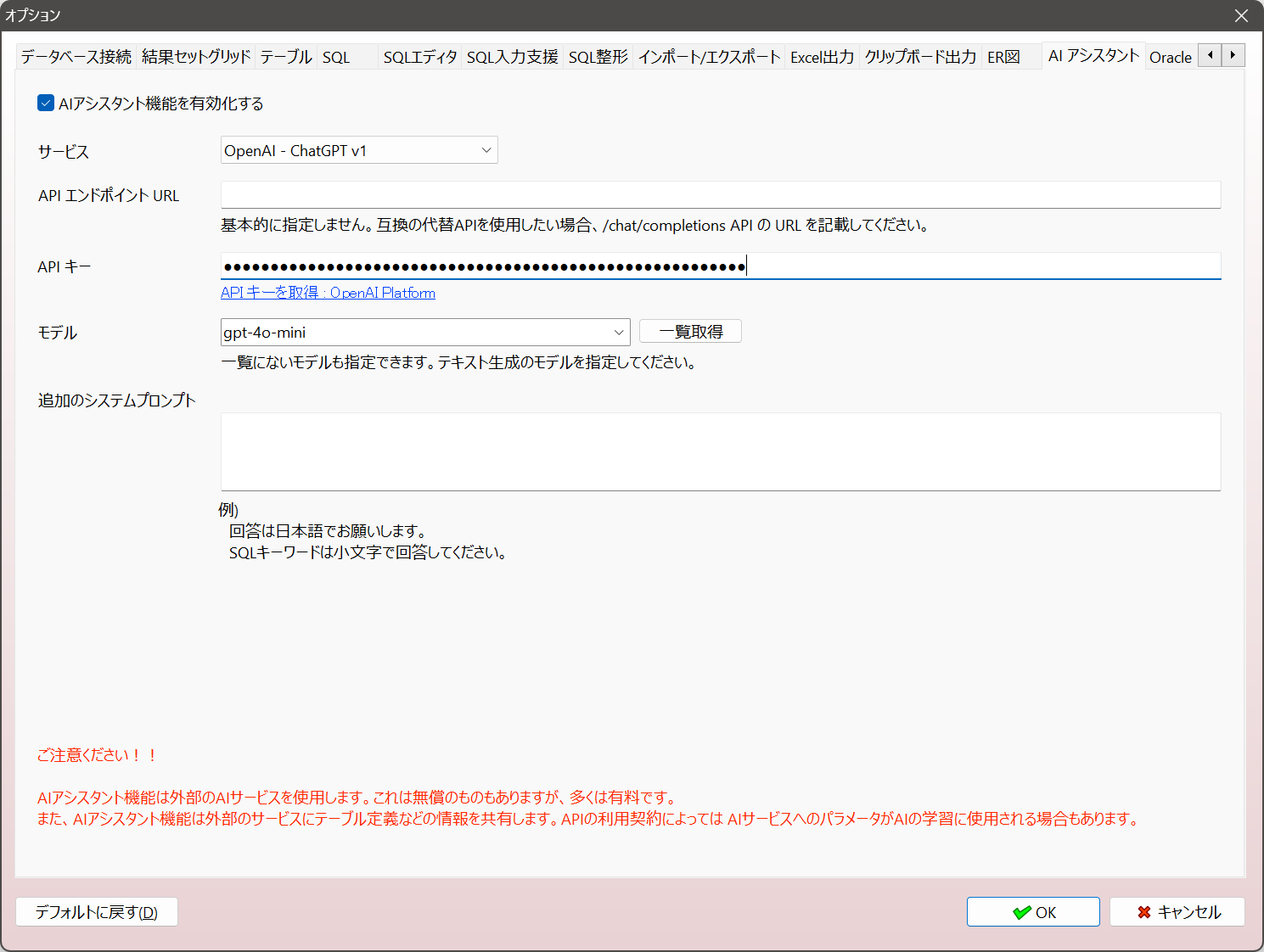
AIアシスタント機能を使うには、オプションダイアログからAI機能を有効にして、使用するAIサービスを登録、設定をする必要があります。例えば、OpenAI の ChatGPT を使用するには、OpenAI Platform でアカウントを登録し、支払い情報を登録してAPIキーを発行する必要があります。
例えば ChatGPT を使用するには、オプションダイアログのAIタブで サービス に OpenAI – ChatGPT v1 を指定し、APIキー を登録、モデル を選択する必要があります。
Open AI Platform は ChatGPT Plus などのチャットサービスとは異なるサービスです。ChatGPT Plusに登録していても別に Open AI Platform に登録する必要があります。AI APIの料金は基本的に従量制です。(単価は使用するモデルにより異なります。)
AIサービスは以下のサービスに対応します。
Anthropic – Claude
Google – Gemini
Microsoft – Azure OpenAI
OpenAI ChatGPT
Ollama (これのみローカルにインストールするソフトウェアで、APIキーの発行は不要です)
1.2 AIアシスタントペイン
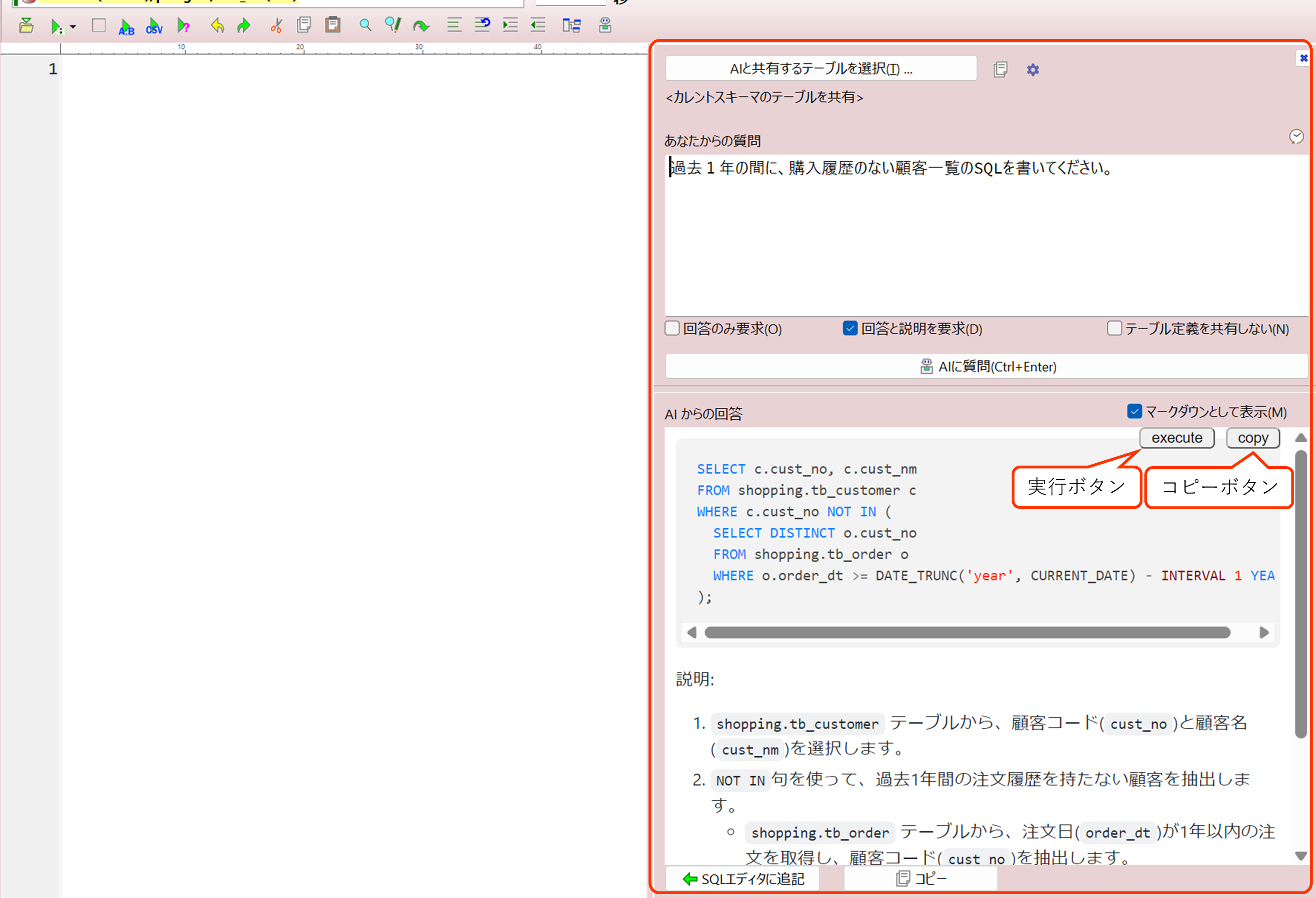
オプションダイアログからAIサービスの設定が完了したら、SQLエディタでメニューから [SQL(S)] – [AIアシスタント(AIペインの表示)(I)] または、Ctrl+I でAIアシスタントペインを開くことができます。
AIアシスタントペインでは様々な質問をすることができます。チャットではないので、前回質問の結果に対しての続きの質問はできません。
AIにSQLを書いてもらう事も出来ますが、AIにデータベースやSQLについて教えてもらうことを主眼に置いた機能です。
他のSQLクライアントのAIアシスタントでは、SQLを直接作ってもらったりすることが多いですが、A5:SQL Mk-2のAIアシスタントペインでは説明を付けてもらう事ができるので、生成されたSQLをより深く理解する事ができます。
AIの回答中のコードはそのままSQLエディタで実行したり、クリップボードへコピーをすることができます。
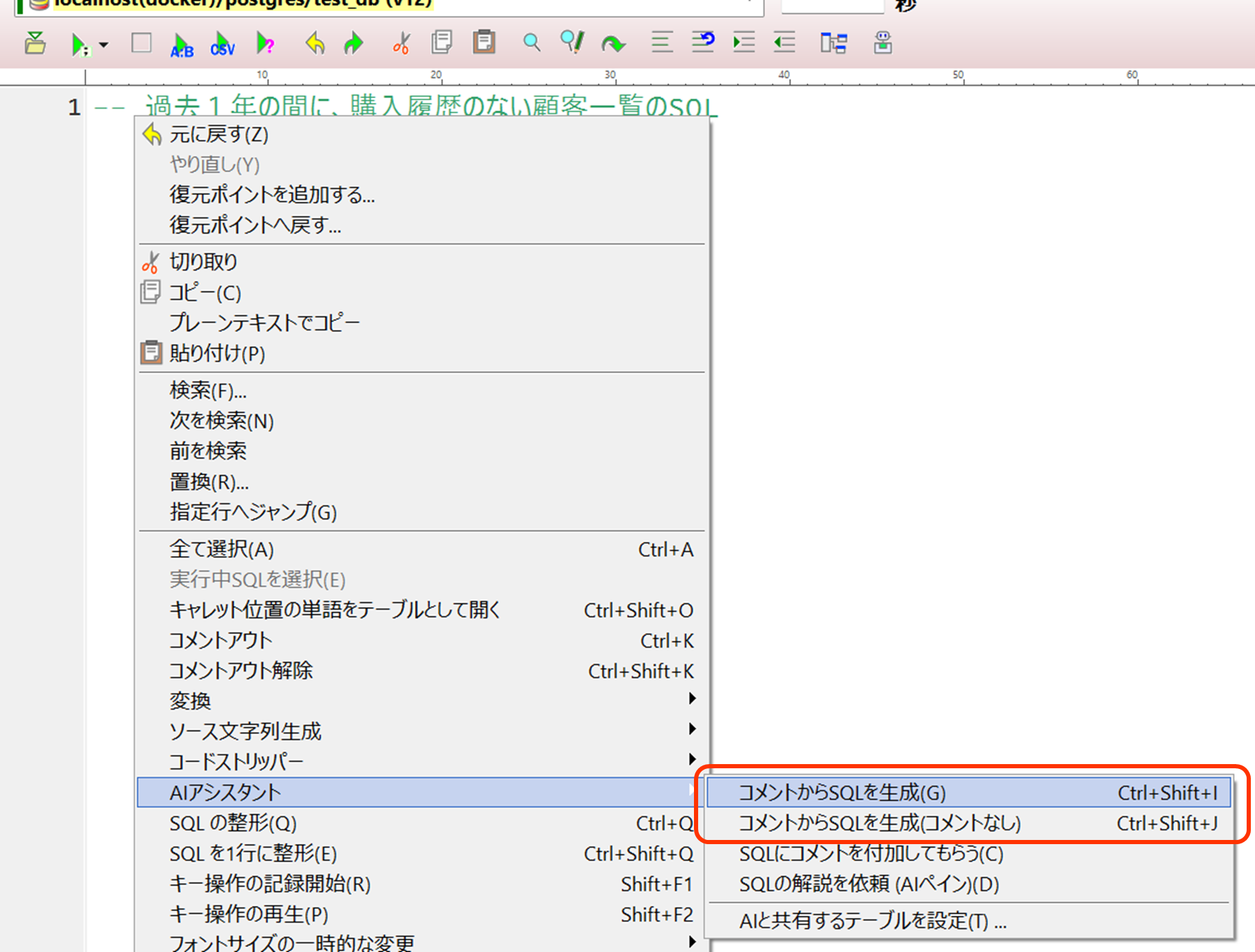
1.3 コメントからSQLを生成
SQLエディタに書いたSQLコメントからSQL自体を記述してもらうことができます。基本的にカラムやテーブルに対してコメントが付きますが、コメントなしで生成することもできます。
生成されたSQLはテキストエディタ中でコメントの直下に挿入されます。
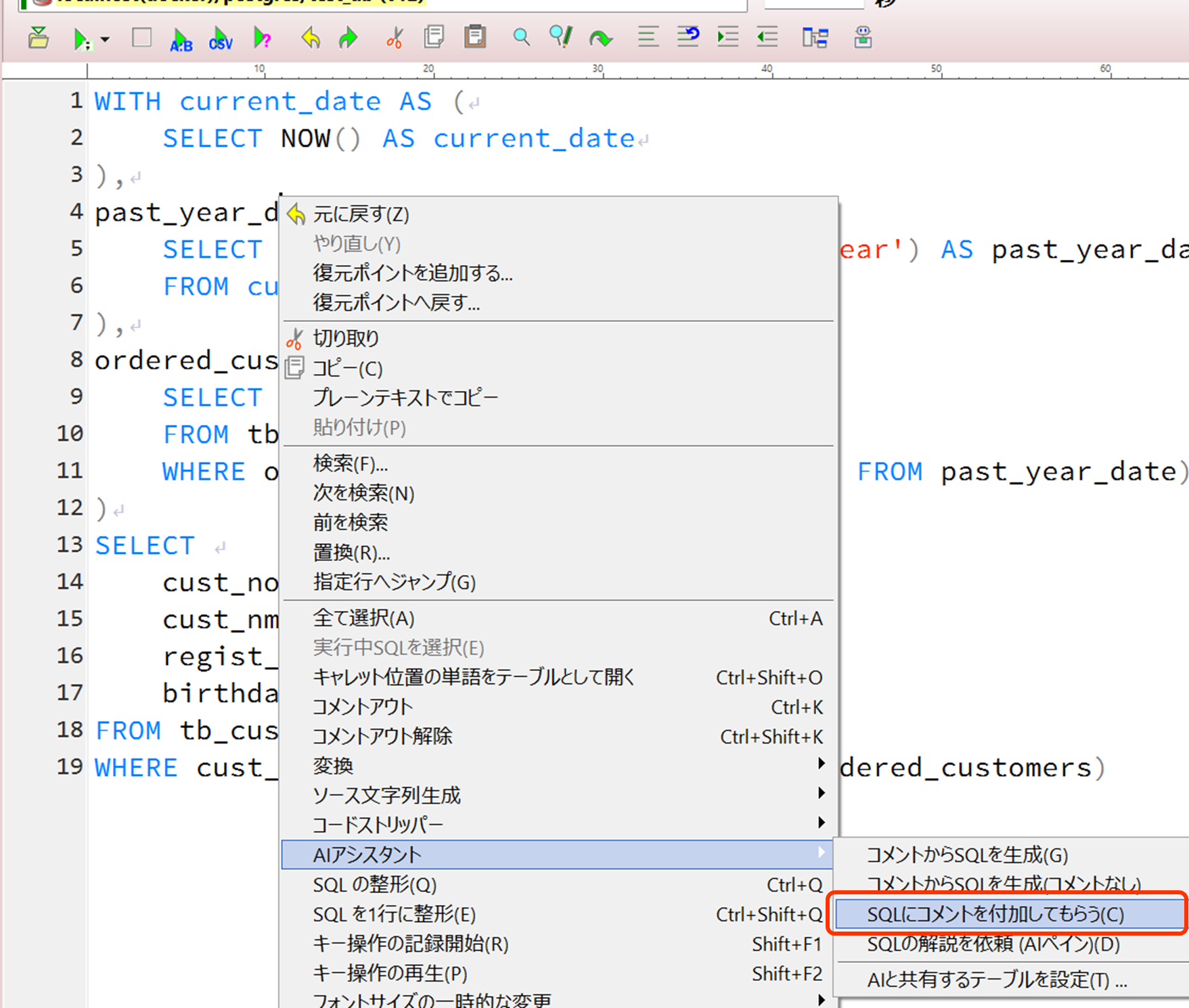
1.4 SQLにコメントを付加してもらう
よくわからないSQLにコメントを付加してもらうことができます。テキストエディタ中のSQLが直接書き換えられます。
結果が気に入らない場合は「元に戻す」(Ctrl+Z)で戻すことも可能です。
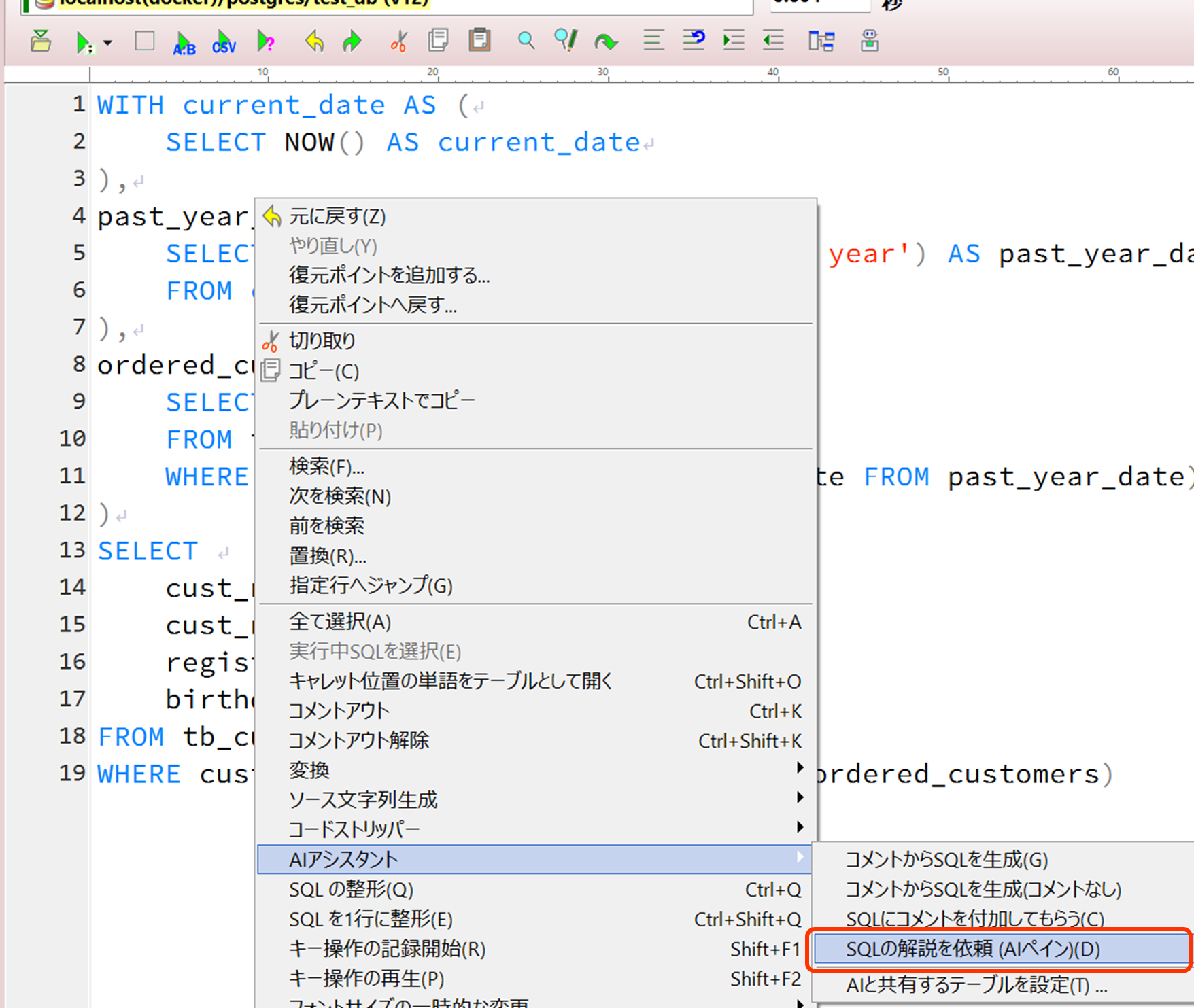
1.5 SQLの解説を依頼
SQLの解説をAIアシスタントに依頼することができます。この機能はAIアシスタントペインが自動で開き、質問して回答を得ることができます。
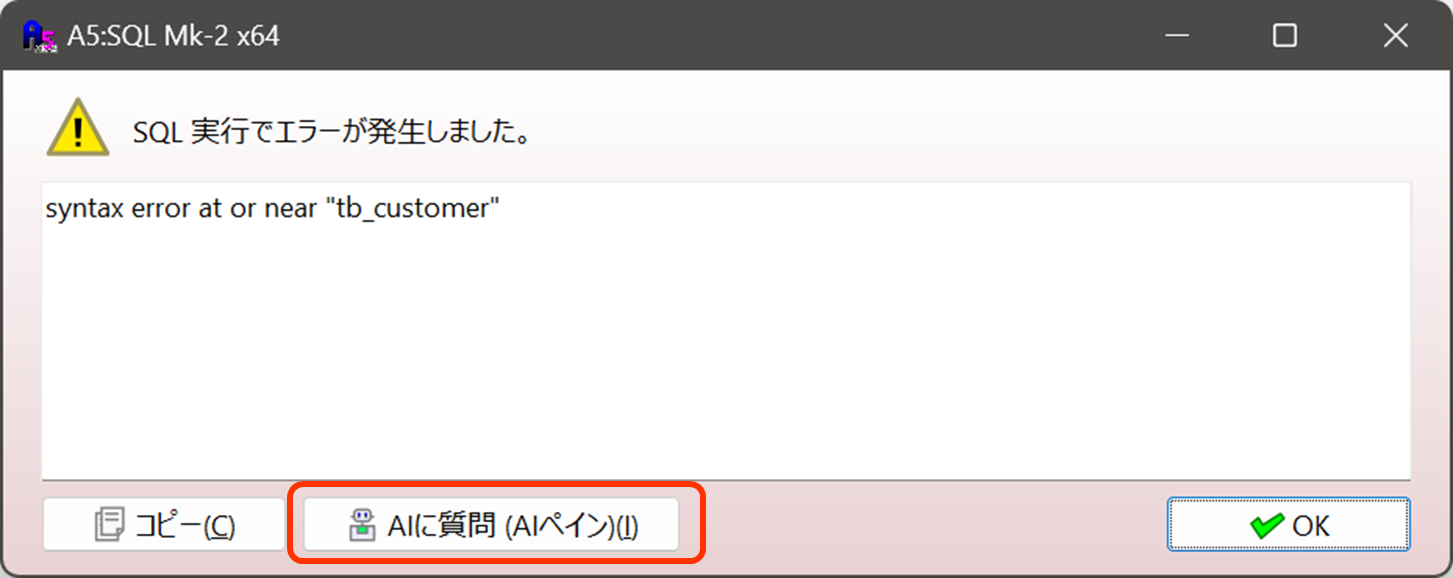
1.6 SQLのエラーをAIに質問
SQLでエラーがあった場合にエラーダイアログが表示されますが、ここでエラーの原因と修正案をAIに質問することができます。この機能では、AIアシスタントペインが開いて自動的に質問・回答を得ることができます。
※AIの回答は必ずしも正確でない可能性があります。
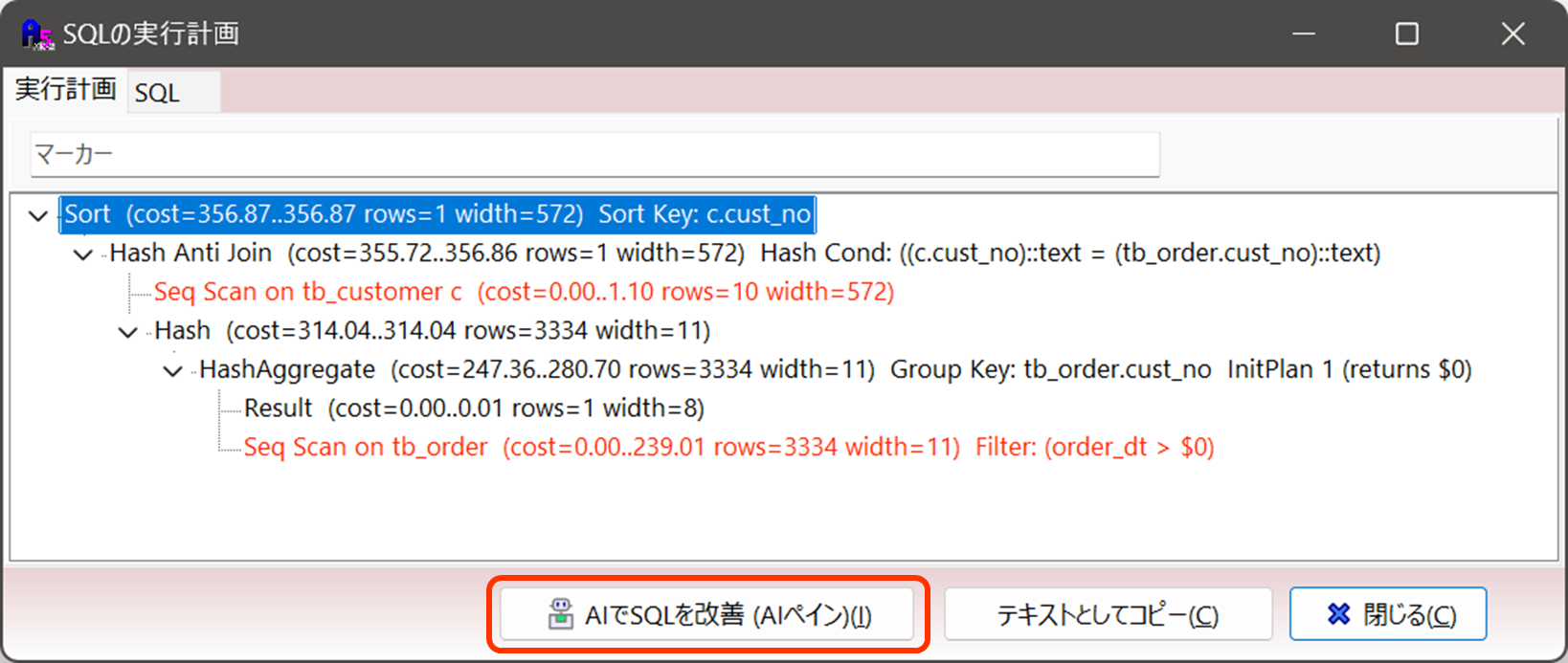
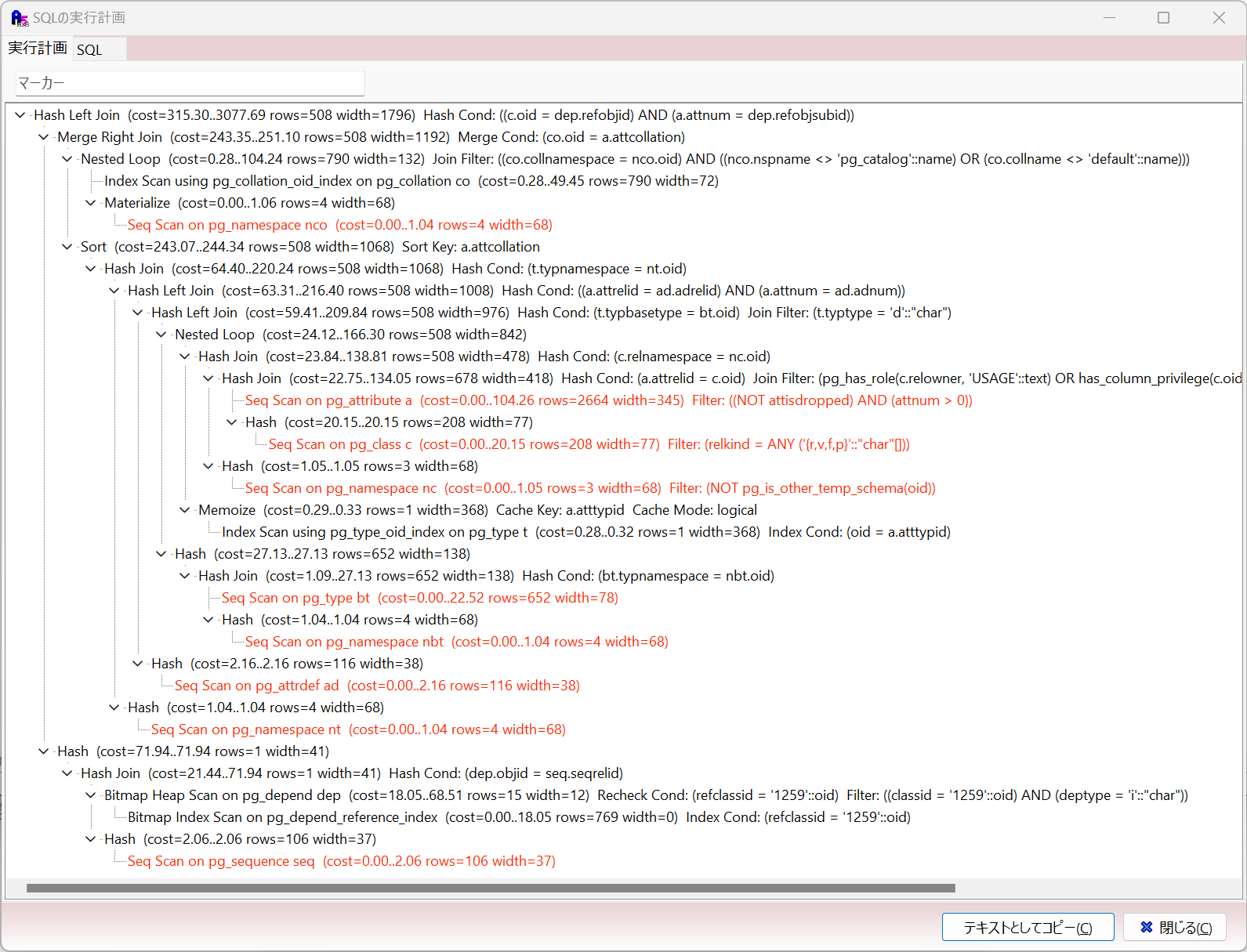
1.7 SQLの実行計画からSQLを改善(パフォーマンスチューニング)をしてもらう機能
SQLの実行計画画面からSQLを改善してもらうことができます。AIアシスタントペインが開いて自動的に質問・回答を得ることができます。
※AIの回答は必ずしも正確でない可能性があります。
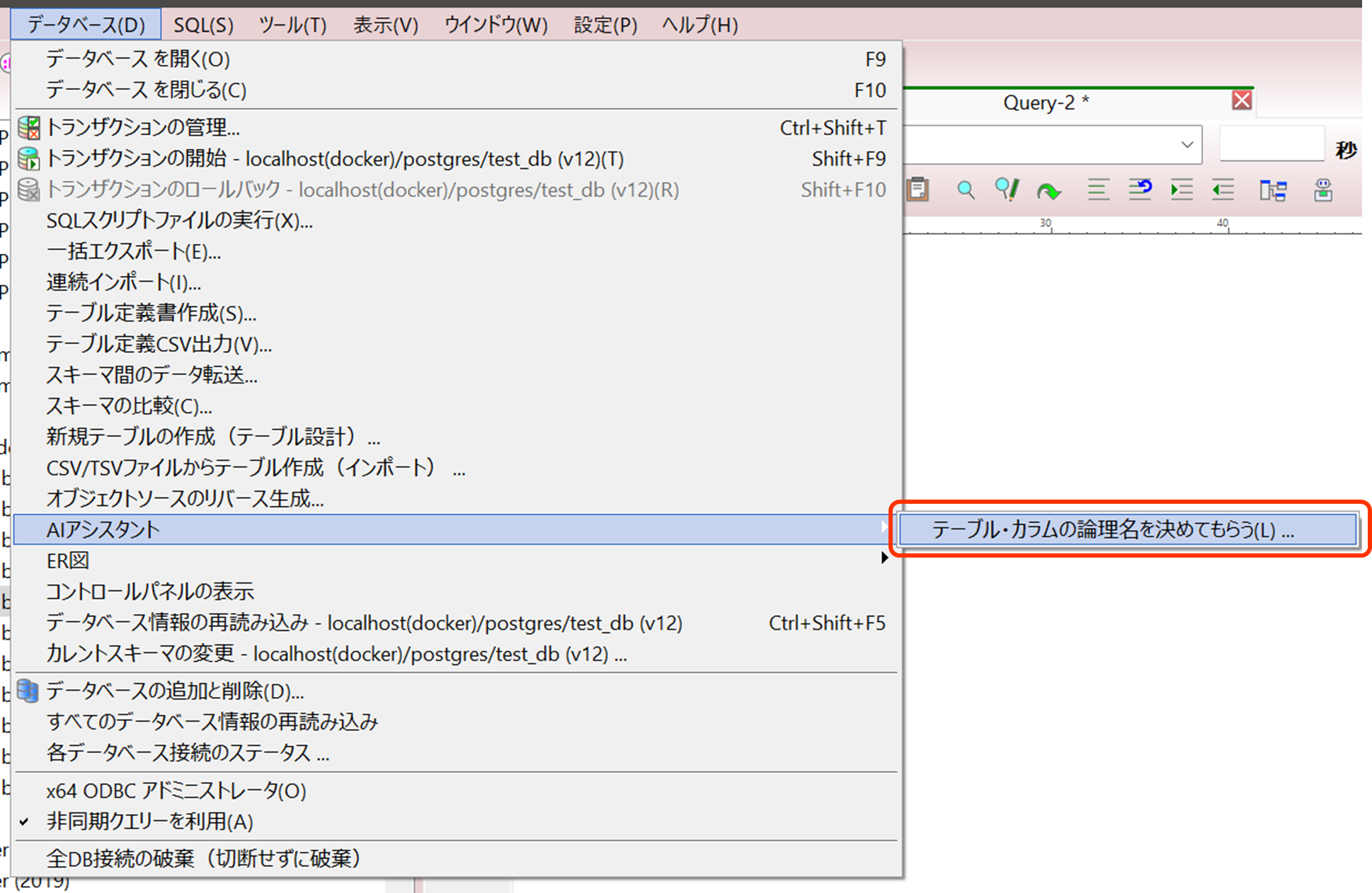
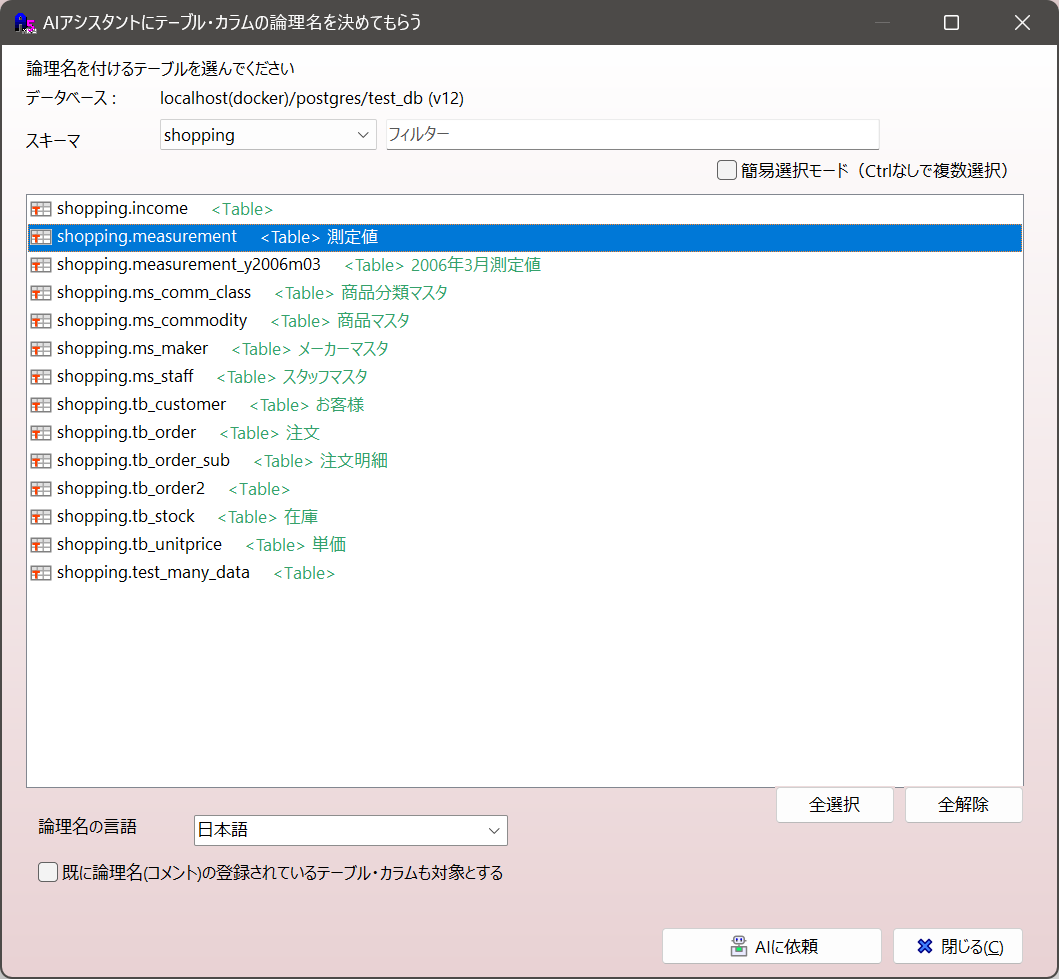
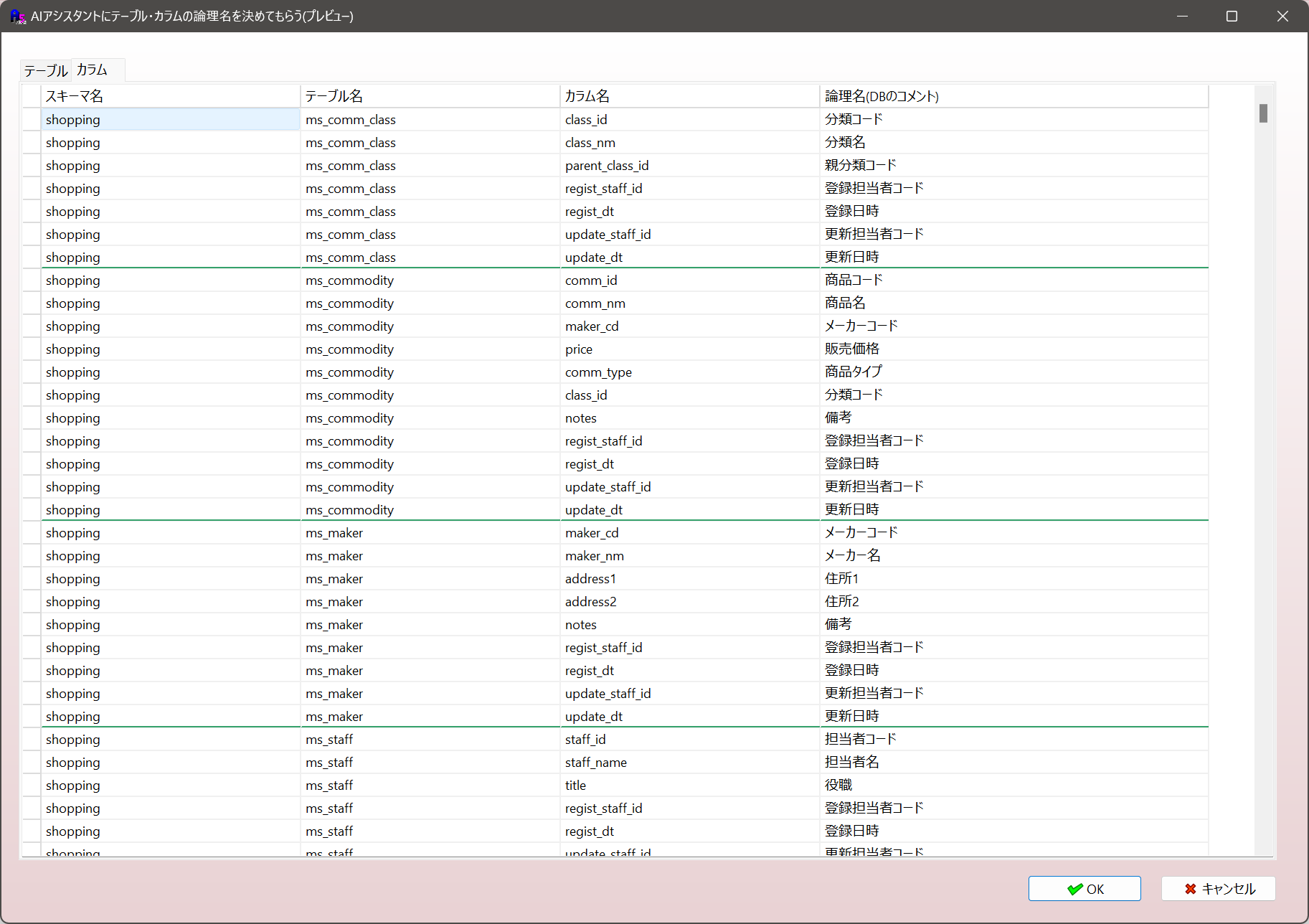
1.8 DBのテーブルやカラム・ER図のエンティティや属性に論理名をつけてもらう機能
テーブル名やカラム名はしばしば英語や英語を短縮したような名前が使用されわかりにくいこともあります。AIに論理名をつけてもらうことで分かりやすくすることができます。
論理名は日本語以外の言語でつけてもらうこともできます。
2. テキストエディタコンポーネントの置き換え
これまでのプロプライエタリのテキストコンポーネントからオープンソースのテキストエディタに置き換えを行いました。これは将来的にA5:SQL Mk-2本体をオープンソースにするための準備の一環です。
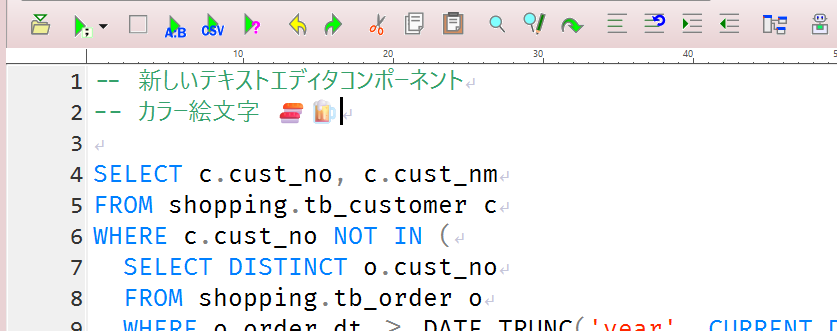
これまでのテキストエディタコンポーネントは古い設計で動作速度も遅かったですが、新しいテキストエディタコンポーネントはこれまでのエディタよりも高速に動作し、64bit版ではカラー絵文字も使用できます。(🍣とか🍺とか)
ただ、これまでのテキストエディタコンポーネントとは多少挙動の異なるところもあるはずなので好みの問題はあるかもしれません。
(コードの折り畳みや矩形選択などができなくなってしまいました)
※A5:SQL Mk-2本体をオープンソースにするといっても、早くても10年後とかの話になるかと思います。
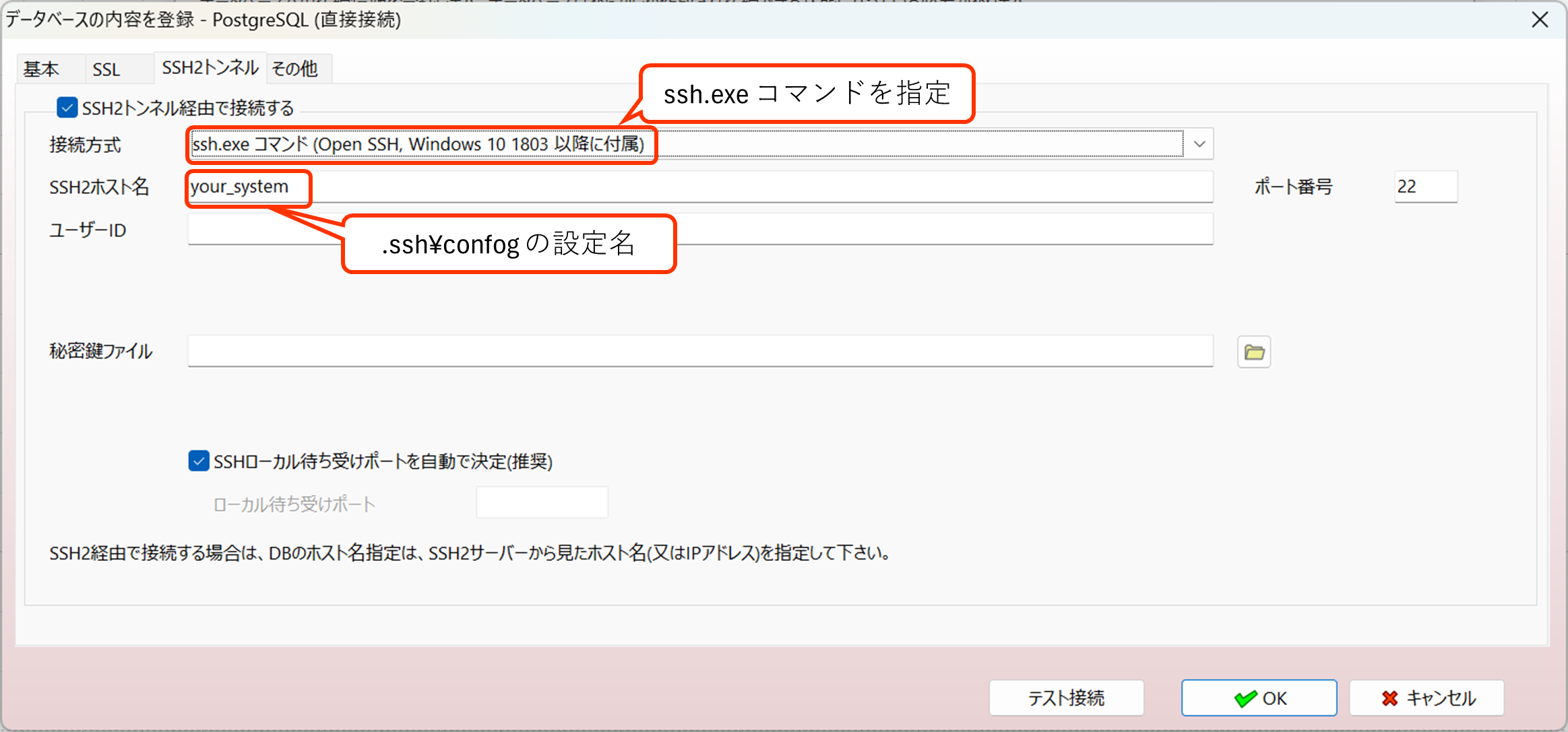
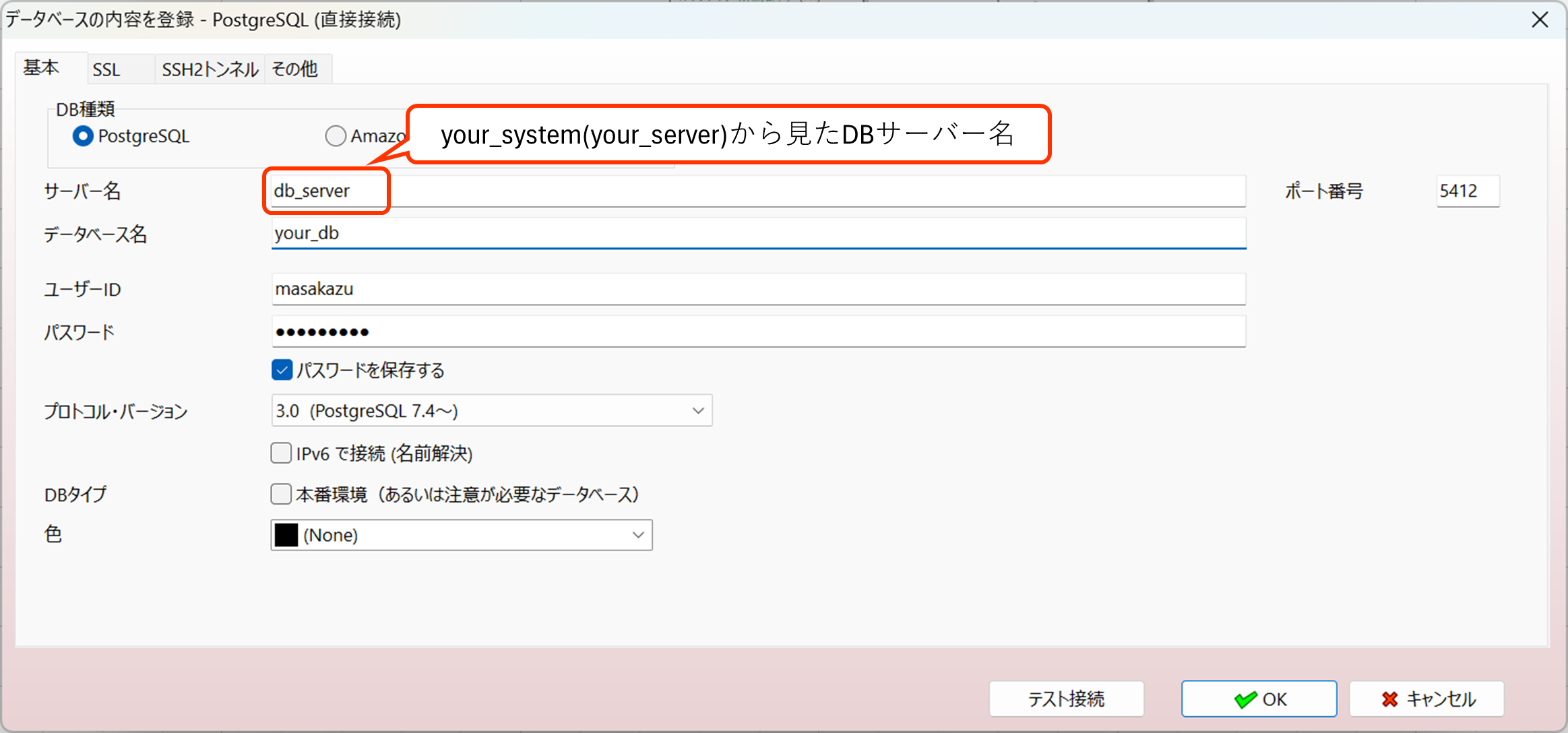
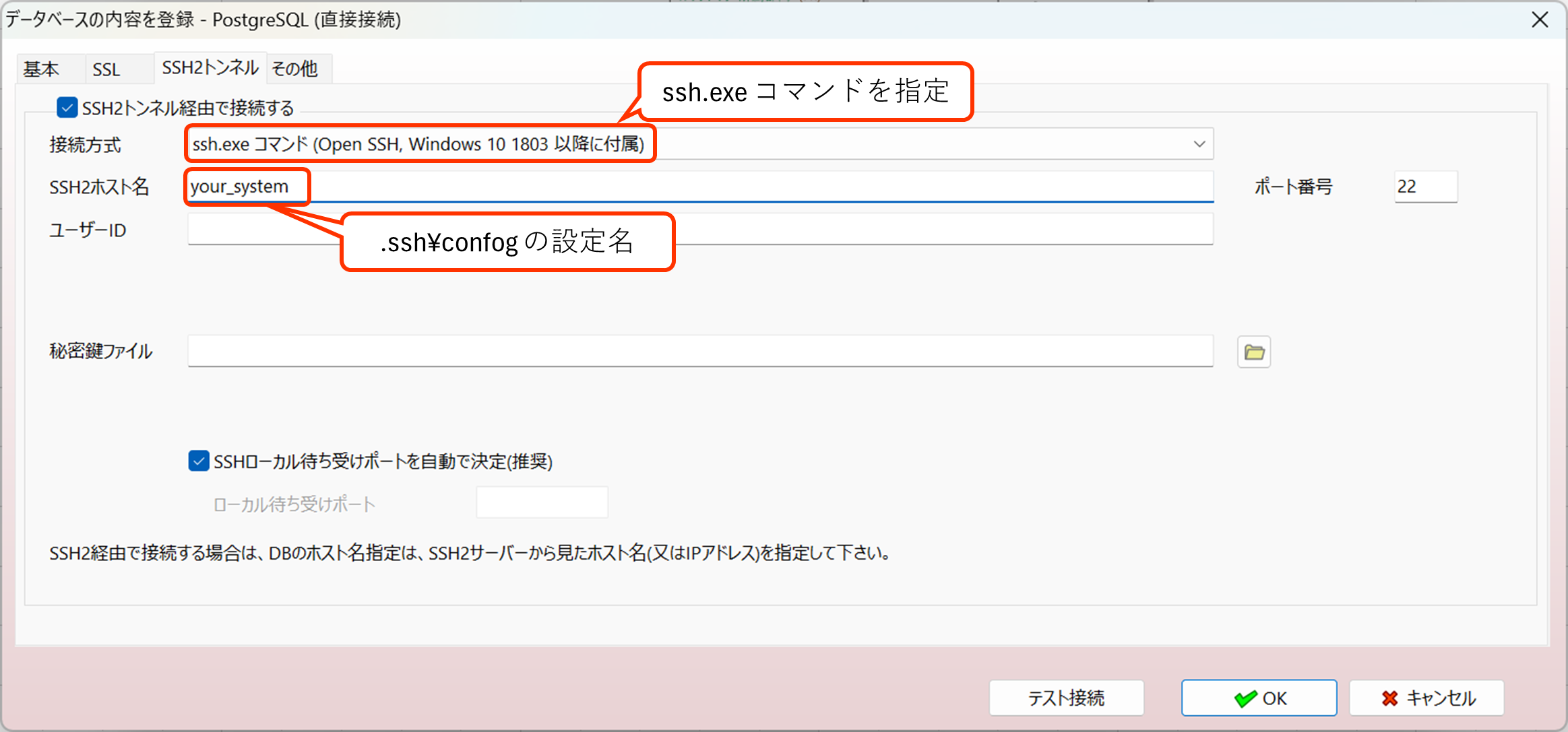
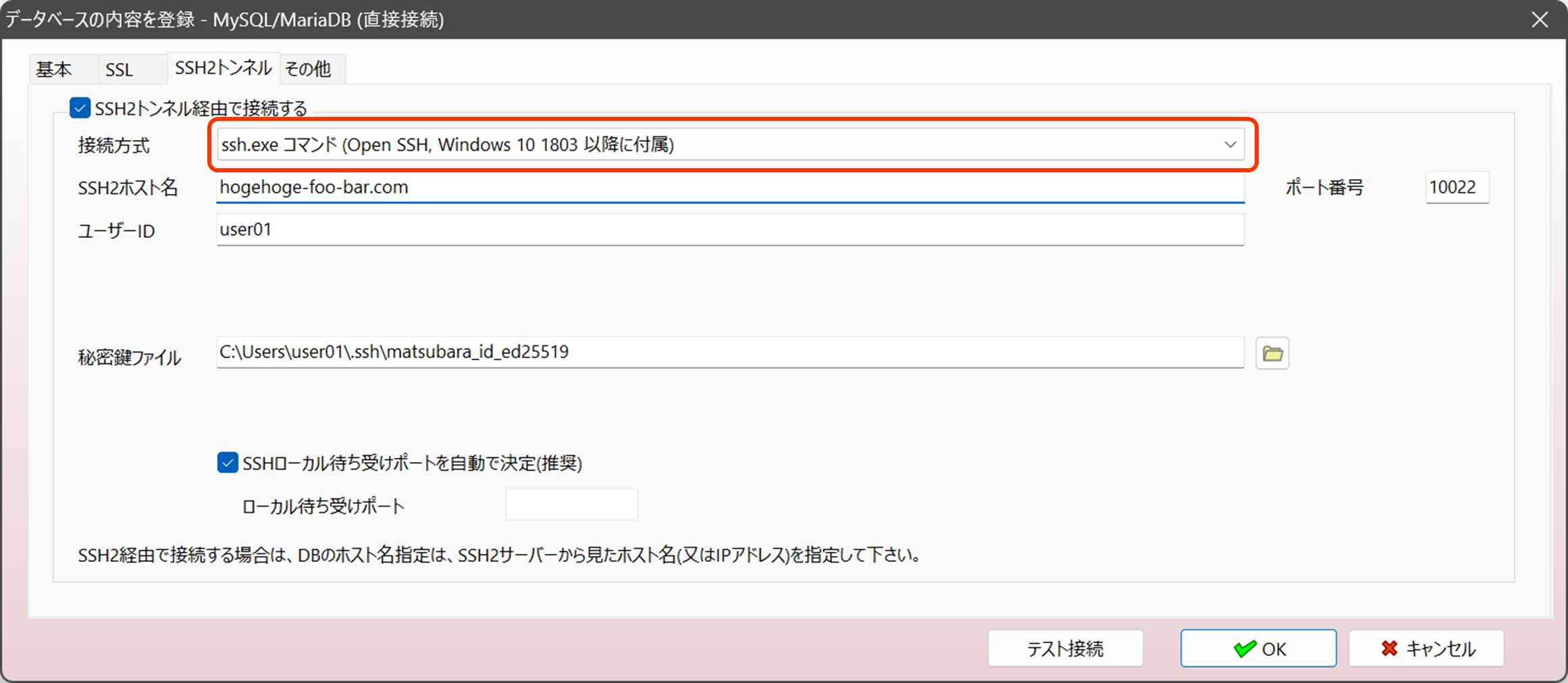
3. SSH経由の接続で、Windows OSに付属するssh.exe を利用して接続できるように変更
これまではA5:SQL Mk-2内蔵のSSHライブラリまたは putty(plink.exe)経由での接続のみでしたが、Windows OSに付属するようになった ssh.exe 経由での接続もサポートするようになりました。
.ssh_confingの記述で多段SSHで接続したり、ssh-agent 経由で鍵ファイルのパスフレーズを管理したりできます。
最後に
Version 2.20 はAI機能に対応したり、近年のアップデートの中でもかなり大型のアップデートとなったように思います。これらの機能が皆様のDB開発のお役に立てればと思います。