
今回は、SQLを書く上で特にパフォーマンスに影響のあるSQLの実行計画の読み方について解説します。実行計画はデータベース製品によってさまざまに差異がありますが、ここでは比較的どのデータベース製品でも共通する内容について解説します。
実行計画とは記述したSQLが実際にデータベースの内部でどのように処理されて結果を返すか、その処理方法を記述した情報です。
A5:SQL Mk-2では、SQLエディタで実行計画を見たい SQL の上にキャレットがある状態でメニューから [SQL(S)] – [SQLの実行計画(J)] または、Ctrl+E で表示できます。
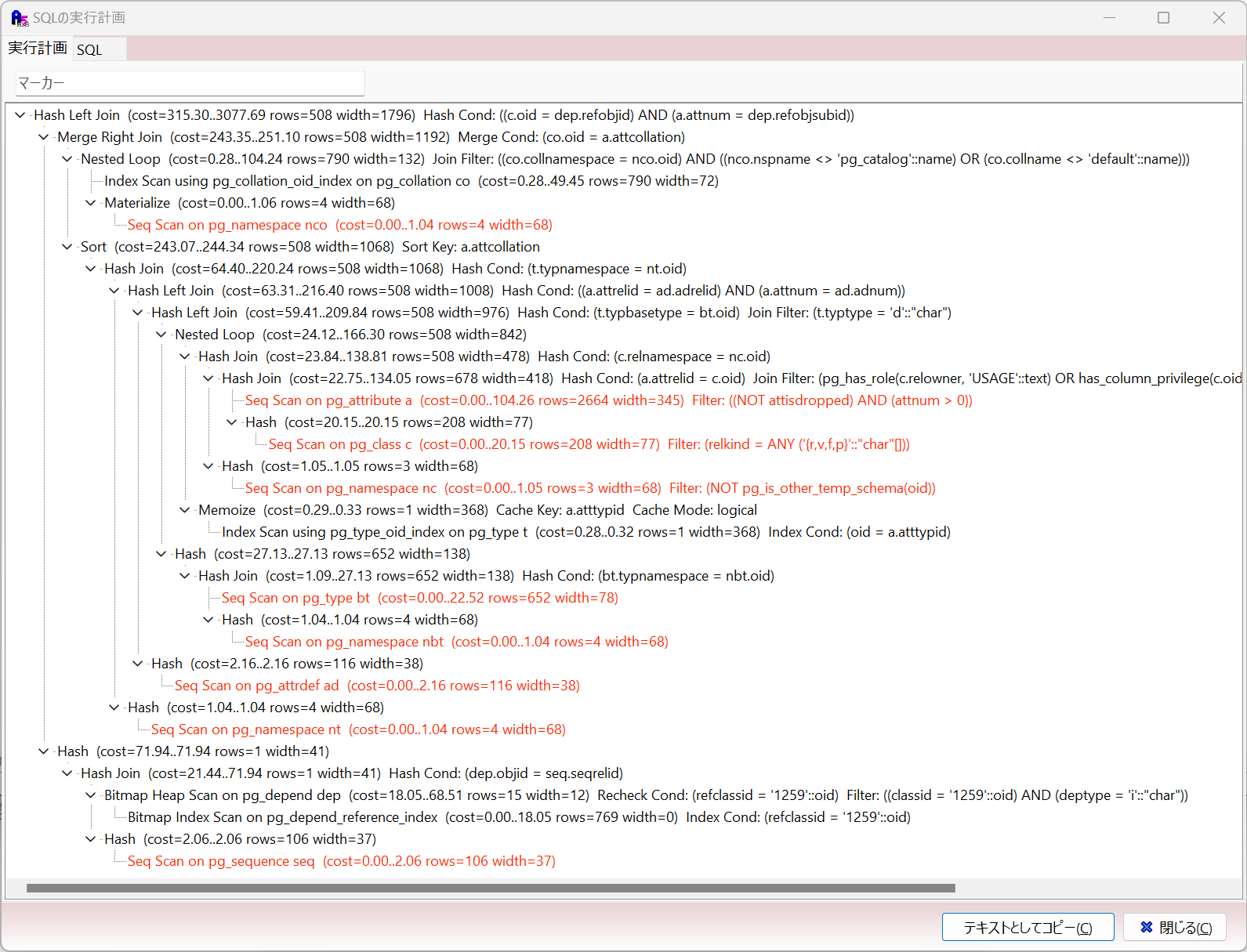
表示の仕方はデータベース製品ごとに異なりますが、多くのデータベース製品ではツリー状の情報として表現されます。(このため A5:SQL Mk-2でもツリービューで実行計画を表示します。)
ツリーのリーフ(端)から処理が行われ、ルート(根)に向かって絞り込み・結合・集計・ソートを行いながら処理されていきます。
まず見るべきは、無駄なテーブルの全体読み込みが発生していないか確認することです。テーブル全体読み込みは、データベースの種類によって表現が異なりますが、TABLE ACCESS FULL (Oracle)・「Seq Scan (PostgreSQL)・ALL (MySQL) などと表示されます。 A5:SQL Mk-2ではこれらの処理は赤字で表示されます。
このとき、マスターテーブルのような、件数の少ないテーブルは全件読み込みが発生していたとしてもそれほど気にする必要はありません。多くの場合、小さなテーブルはデータベースのバッファキャッシュ(メモリ)から高速に読みだされます。大きなデータを持つトランザクションテーブルが全件読み込みになっている場合は注意が必要です。あと、赤字でないからと言って全件読み込みが発生していないとは言い切れないので注意が必要です。
大きなデータのテーブルで全件読み込みが発生している場合、インデックスの追加を検討する必要があります。絞り込みを行っているカラム・結合を行っているカラムでインデックスの追加を検討します。
また、サブクエリーを使っているSQLなどではサブクエリーの見直しを検討するのもよいかと思います。
インデックスの有無で後述するテーブルの結合方式も変わってきます。
テーブルの結合の仕方について。
テーブルの結合はデータベース製品によって様々ですが、大きく分けると内部的にネストループジョイン・ハッシュジョイン・ソートマージジョインの3つの方式が使い分けられることが多いです。(データベース製品によっては特定の結合方式がないケースや別の結合方式がある場合もあります。)
基本的にはどの方式が採用されるかはデータベース製品自体が選択します。それぞれについて説明します。
- ネストループジョイン
ネストループジョインはそれぞれのテーブル(あるいはサブクエリーの結果セット)を2重ループで結合させる処理と思えばよいです。ただし、一般的には内側のテーブルはループではなくインデックスによるアクセスで実現されます。外側のテーブルは小さめのテーブル(全件スキャンかも)で、内側のテーブルは大きなテーブル(インデックス付き)のようなケースで使用されます。
外側のテーブル・内側のテーブルは必ずしもSQLでの記述順序とは限りません。(多くのデータベース製品ではどちらが外側・内側かは自動的に判断されます。)
- ハッシュジョイン
ハッシュジョインは、片側のテーブル(データベースが小さいと見積もったテーブル)が結合するキー項目でメモリ上のハッシュテーブルに格納されます。もう片方のテーブルを読み込みつつ、ハッシュテーブルと突き合わせます。ハッシュテーブルを作成する処理が前処理として必要になります。
- ソートマージジョイン
ソートマージジョインは、双方のテーブルともあらかじめ結合条件のキー項目でソートします。その後、マージ処理でキー項目を突き合わせつつ結合を行います。双方のテーブルをソートするための前処理が必要となります。またテーブルが大きくメモリに読み込めない場合、一時ファイル等に書き出されます。キー項目にインデックスが付く場合、インデックスを使ってテーブルを読み込むことでソートの代替とすることがあります。
これら3つの結合方式のうち、どれを採用するか(どれが速いと考えられるか)はデータベース製品自身が判断しますが、ハッシュジョイン・ソートマージジョインについては前処理が必要であることがパフォーマンスに影響する場合があります。結果的に結合結果の表の件数が少ない場合、前処理に時間がかかる分、ハッシュジョイン・ソートマージジョインは遅くなりがちです。また、全件結果を返す時間はともかく、最初の1件を返し始める時間は遅くなります。逆にネストループジョインは最初の1件目を返すのが速い代わりに全件返す時間は遅くなる場合があります。思い通りの結合方式になっていない場合は、インデックスを追加したり、書き方を変える必要があります。
いくつかのデータベース製品では「ヒント句」などを指定することで、どのような結合方式を採用するか・どのインデックスを使うかをある程度制御できます。
できるだけ高速な読み込み方法・結合方法を採用するために、判断基準として各データベース製品は統計情報(データの件数や種類・偏り等々)をバックグラウンドで収集します。多くの場合は自動で採取されます。大量データを投入した直後などは統計情報が実データとあっておらず、遅い実行計画になってしまうことがあります。この場合、手動で統計情報を取得するコマンドがあったりするので、それを活用すると速い実行計画になることがあります。
この記事では実行計画の読み方・パフォーマンスチューニングに関する考え方はここまでにします。遅いSQLがある場合はこの実行計画を見ながら、どのようにSQLを修正する・インデックスを追加するを考えていくことになります。